O mundo atual dificilmente pode ser considerado um lugar seguro. Os conflitos regionais e étnicos têm crescido de forma desmesurada ou, pelo menos, temos mais consciência de que eles existem. Estima-se que apenas no século passado foram mortos duzentos milhões de indivíduos em guerras e outras desavenças entre grupos humanos (Woolf & Hulsizer, 2004). No século XXI, a presença diuturna dos meios de comunicação tem contribuído para documentar, tornar público e oferecer um destaque ainda maior aos conflitos. A transmissão ao vivo dos ataques às Torres Gêmeas em Nova Iorque e a subsequente guerra ao terror proclamada pelo presidente George Bush e espetacularizada na cobertura ao vivo dos bombardeios a Bagdá, capital do Iraque, foram acontecimentos emblemáticos e anteciparam, em certa medida, a situação atual do mundo em que vivemos.
Este contexto nos impede de considerar justificada a interpretação exageradamente otimista de que as formas flagrantes de preconceito e discriminação desapareceram sob o peso do politicamente correto e das pressões no sentido de reduzir a expressão aberta dos preconceitos. Os assédios sobre as diferenças e os diferentes se acirraram. Muitos grupos usam a internet e os meios de comunicação de massa para expor as suas doutrinas e atrair adeptos, o que faz com que a intolerância esteja presente em um número cada vez maior de espaços de convivência. Os separatismos, os grupos armados e os movimentos de contestação pipocam por toda parte e em todos os cantos. Os fundamentalismos, particularmente o religioso, parecem se impor em muitos países onde a ideia de uma sociedade secular vem paulatinamente perdendo importância. Os antagonismos políticos se tornam mais acirrados e as diversas organizações políticas desencadeiam, a cada dia, mais e mais manifestações nas quais tornam pública as suas insígnias, o que significa oferecer visibilidade para símbolos e palavras de ordem fascista e autoritárias.
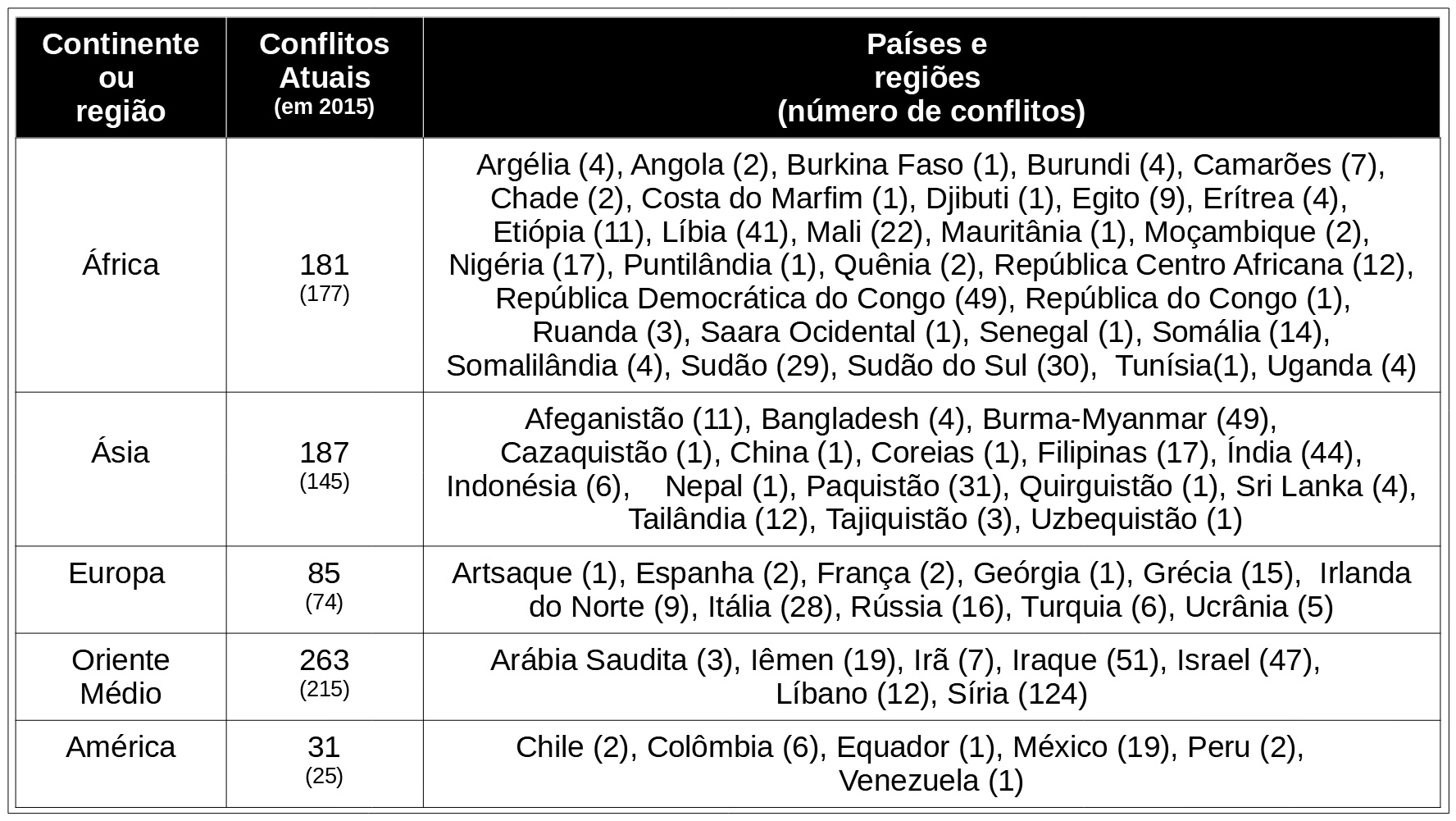
Apesar dos esforços de organismos voltados para patrocinar a paz entre os povos, o número de conflitos não tem sofrido reduções substantivas. Não é uma tarefa fácil acompanhar as estatísticas sobre as guerras nos dias atuais, pois, a cada dia surgem novos focos de conflito e novas zonas de contenciosos. De acordo com o site Wars in the World, um reconhecido meio de registro e documentação de conflitos e beligerâncias, no mês de setembro de 2019 foram contabilizados um total 747 conflitos armados que, se comparados com os 636 que tínhamos registrados em março de 2015, representa um acréscimo considerável em um curtíssimo período. O quadro 14 traz o número de conflitos e os países onde eles foram documentados; devemos assinalar, no entanto, que o registrado se refere apenas aos movimentos de maior visibilidade, isto é, conflitos nos quais estão envolvidos países ou regiões em busca de autonomia política. Em todos os continentes é possível documentar ações de grupos separatistas ou independentistas; além do mais, devemos considerar os conflitos locais de pouca envergadura que também criam importantes dissensões em praticamente todos os cantos. É nesse contexto que o problema das identidades nacionais e étnicas ganha importância; ademais, se acrescermos a este cenário desolador algumas observações acerca do ressurgimento dos fundamentalismos religiosos anteriormente referidos, teremos uma vaga ideia de quão importante se reveste o estudo dos estereótipos nos nossos dias.
O encontrado apenas reflete a face visível e institucionalizada do problema da intolerância que se encontra presente em todos os sítios, mesmo em países nos quais os conflitos ainda não se transformaram em atos de beligerância explícita. Com o advento da internet, grupos de ódio foram fomentados com muita facilidade e, ainda pior, receberam atenção e acolhida de uma parcela nada desprezível da população.
3.6.1. Imigrações e guerra ao terror
No final do século XX, os dois principais centros de pesquisa na área da psicologia social, Estados Unidos e Europa, passaram a enfrentar diferentes desafios. Na América do Norte o horizonte foi marcado por mais uma guerra, a denominada guerra ao terror, enquanto a Europa se deparou com o desafio dos intensos fluxos migratórios oriundos da Europa Central e do Norte da África. Estes dois fenômenos não só exerceram impacto nos sistemas políticos e nas estruturas governamentais, como também foram decisivos para a efetivação de profundas modificações no cenário político e eleitoral. Muitas manifestações discursivas, centradas na noção de ameaças externas, facilitaram o crescimento de estratégias eleitorais baseadas no medo, o que se refletiu na identificação cada vez mais acirrada de inimigos internos e externos. Com isso, desenvolveu-se o temor de que inimigos, até então invisíveis, poderiam adentrar sorrateiramente em território reputados como invulneráveis e a qualquer momento atentar contra a segurança da população, colocar em cheque os valores da civilização e usufruir os benefícios de segurança social que deveriam ser reservados exclusivamente para atender às necessidades da população local.
Os efeitos destas transformações, ainda que diferentes a depender do cenário, acarretaram um mesmo movimento de intensificação da xenofobia e favoreceram a aceitação de medidas restritivas em relação aos imigrantes e, por extensão, a todos os não integrados à sociedade. Partidos políticos conservadores se aproveitaram dessa pauta e, com discursos que privilegiavam cada vez mais os argumentos autoritários e nacionalistas, encontraram eco em uma população amedrontada e insegura, alcançando um crescimento que, definitivamente, não se esperava. Conforme consideramos no capítulo 2, os fluxos migratórios não constituem fenômenos recentes na trajetória das sociedades humana. Se os imigrantes conquistam alguma estabilidade econômica e sucesso social, a percepção se mostra negativa, pois são vistos como ameaça ao emprego ou aos negócios dos locais; se fracassam economicamente, também são avaliados de forma negativa, pois tendem a ser responsabilizados pelos problemas que afligem a sociedade que os recebe (Pettigrew, Wagner, & Christ, 2007).
3.6.2. Bots e Big Data
Acentuamos, durante a discussão das transformações sociais ocorridas nas últimas décadas, o papel desempenhado pela tecnologia da informação, em particular, o uso cada vez mais corriqueiro de dispositivos computacionais e, atualmente, de dispositivos móveis, como os celulares e vestíveis. Como era de se esperar, as transformações sociais e tecnológicas proporcionaram mudanças acentuadas em muitos setores, inclusive nos hábitos cotidianos, particularmente naqueles associados com as relações interpessoais e intergrupais. Se até então as formas diretas de discriminação, tanto as abertas quanto as sutis, se manifestavam prioritariamente no âmbito das interações presenciais, com o advento da internet, a enorme popularização das redes sociais com o Orkut inicialmente e posteriormente o Facebook e dos programas de comunicação instantânea como o WhatsApp, a expressão dos estereótipos e dos preconceitos alcança um outro nível de difusão e de impacto na sociedade.
É interessante notar que no final do século passado as expectativas a respeito do impacto da tecnologia da informação eram, sobretudo, positivas. Schaff (1995) analisou as consequências da então denominada revolução informática no plano das relações sociais, culturais e políticas e destacou a possibilidade do surgimento de um “homem universal”, tanto na sua formação global e alheio à especialização marcante dos dias atuais quanto na sua libertação do “enclausuramento em uma cultura nacional”. Esperava-se que a revolução da informação provocasse um extraordinário enriquecimento dada a automação da produção, inevitavelmente acompanhada pela fartura material e por uma notável abundância nas informações disponíveis a toda a humanidade. Estas transformações, imaginava Schaff, por certo iriam gerar uma ruptura decisiva no isolamento dos indivíduos, proporcionando a libertação da alienação, rompendo-se, finalmente, com o isolamento em compartimentos profissionais, nacionais e de classe.
Conforme assinalaram Kiesler, Siegel e McGuire (1984) num trabalho em que avaliaram os efeitos da comunicação mediada por computadores, o problema se analisava sob uma outra perspectiva de acordo com a psicologia social da época. Uma primeira dimensão da comunicação mediada por computadores estava associada com uma forte pressão em relação ao rápido processamento da informação transmitida e a tendência correlata de pronta resposta por parte do destinatário. Em segundo lugar, a comunicação mediada por meios eletrônicos se mostrava relativamente insensível aos mecanismos reguladores através da retroalimentação, dada a impossibilidade de obter dados importantes na comunicação tradicional, tais como meneios de cabeça, sorrisos, troca de olhares, distância e postura do interlocutor, tom de voz, assim como os demais aspectos não-verbais da fala. Além disso, importava assinalar, à época, que na comunicação mediada por computadores os dados relativos à posição social e ao status do interlocutor pareciam desempenhar um papel modesto, frequentemente nivelando socialmente todos os participantes. Um aspecto decisivo da comunicação mediada pelos computadores, tal como se concebia, era a relativa anonimidade social, decorrente de uma certa despersonalização induzida pelo meio. Finalmente, por se tratar de um recurso ainda novo e pouco explorado, alertavam que a comunicação mediada por computadores permanecia controlada por pessoas que possuíam um certo domínio da subcultura computacional, não tendo se imposto, ainda, uma etiqueta hegemonicamente aceita para regular a comunicação eletrônica.
Próximo ao final do século XX, a concepção predominante assegurava que a escassez de informações sobre o contexto, aliada à ausência de um consenso quanto às normas que regem este tipo de comunicação, impunham uma série de características à comunicação mediada por computadores:
- A falta de mecanismos de feedback e a ausência de consenso sobre o estilo da comunicação terminariam por dificultar o entendimento das mensagens;
- O poder de influência dos comunicadores tenderia a ser reduzido, uma vez que as hierarquias e as informações relativas ao poder exercido pelos interlocutores tenderiam a ser ocultadas; e
- Como os padrões tradicionais de regulação dos encontros sociais perderam importância, a comunicação se tornou relativamente impessoal, pois a atenção se dirigia mais para o conteúdo da mensagem em si mesmo do que para as intenções do interlocutor.
Esta posição pessimista estava numa clara oposição à visão algo tranquilizadora de Schaff, o que tornou visível um acirrado debate entre os defensores de duas posições doutrinárias: de um lado, os que viam esta modalidade de comunicação como demasiadamente superficial, hostil e impessoal, enfatizando que o máximo que ela poderia oferecer seria uma certa ilusão de comunidade; no plano oposto estavam perfilados os que defendiam o ponto de vista de que a comunicação mediada por computadores seria o caminho pelo qual a humanidade se libertaria das relações interpessoais da confinação imposta pelos limites de tempo e lugar, podendo-se esperar a criação de oportunidades para o surgimento de novas modalidades de interação entre pessoas ou comunidades (Park & Floyd, 1996).
Balizados por este debate e numa época anterior à da internet, utilizamos um sistema implementado em microcomputadores, conhecido por BBS (Bulletin Board System), para conduzir uma pesquisa em um fórum eletrônico de uma rede de BBSs brasileiras e portugueses. A pesquisa resultou na tese de doutorado Rosenberg, Iceberg… é tudo a mesma coisa: humor e estereótipos étnicos no ciberespaço. O título da tese alude a uma anedota a respeito de uma pessoa que encontra casualmente um judeu, conhecido por Sr. Rosenberg e, de forma inesperada, ao ser apresentado ao Sr. Rosenberg aplica um inesperado e potente murro no rosto do Sr. Rosenberg para em seguidas proclamar: isto é pelo Titanic! Admoestado por um circunstante que o tristemente famoso navio fora levado a pique por um iceberg, o agressor não mede as palavras e expressa a frase que deu título à tese: Iceberg, Rosenberg, Kronenberg… é tudo a mesma coisa.
A pesquisa foi um estudo ex post facto, no qual acompanhamos a troca de mensagens no fórum eletrônico de discussão Anedotas da rede Lusonet. O acesso era obtido por meio de um modem de 2400 bps, vinculado a uma linha telefônica. Para que alguém não monopolizasse a porta do modem e impedisse o acesso de outros usuários igualmente ávidos, os programas gerenciadores de BBSs ativavam um dispositivo que limitava o acesso de cada usuário a uma hora diária. Desse modo, tínhamos que utilizar os leitores offline de mensagem que faziam uma busca pelos fóruns previamente subscritos, o download das mensagens ainda não lidas e o upload das mensagens respondidas durante a sessão offline. O BBS On The Wall, localizado na cidade de Juiz de Fora, dispunha de um gerenciador de boletins eletrônicos que, de duas a três vezes por semana, conectava-se à rede, buscava as novas mensagens postadas nos diversos fóruns e as distribuía para os usuários.
Acompanhamos a troca de mensagens por oito meses, sempre atentos às interações por meio de postagens, réplicas e tréplicas que se seguiam a uma mensagem original, geralmente uma ou mais anedotas, contadas por portugueses e brasileiros. Um dos nossos principais objetivos foi estimar o grau de afetividade de cada mensagem, donde elas terem sido classificadas como neutras, positivas ou negativas por três juízes. Os resultados permitiram identificar que, do total de 561 postagens, 15,4% foram classificadas como positivas, 18,9% como neutras e as restantes 65,7% como negativas. Tais dados apontam para um cenário no qual os afetos negativos associados ao conteúdo das comunicações mediadas por computadores se mostraram muito frequentes, o que reforçava a posição dos que sustentavam o efeito disruptivo da tecnologia da informação, embora seja importante considerar que esta tendência poderia apenas refletir a natureza peculiar do fórum onde as mensagens foram postadas, parecendo-nos lícito supor que se fossem analisadas mensagens postadas em outros fóruns, por exemplo, os de tecnologia ou amizade, os resultados teriam sido bastante diferentes.
Os objetivos centrais das análises foram os de registrar as manifestações estereotípicas, tais como se exprimiam no conteúdo das piadas, bem como identificar o contexto das relações entre os grupos ou as categorias que presidia a manifestação das anedotas. As relações podiam ser endogrupais, quando a unidade de interação era composta unicamente por brasileiros ou por portugueses, ou exogrupais, quando brasileiros e portugueses compartilhavam um mesmo tópico durante a troca de mensagens. Como esperado, as relações exogrupais se mostraram menos cordiais, pois, apesar do esforço dos moderadores do fórum para manter um verniz civilizatório nas comunicações, raramente as mensagens podiam ser qualificadas como amistosas. Os brasileiros, quase sempre a tratar os portugueses como estúpidos, enquanto estes não vacilavam em qualificar aos brasileiros como animais imundos.
Pode-se estabelecer uma enorme diferença, em termos de estereotipização, em ser qualificado mediante a aplicação de um adjetivo (estúpido) ou de ser tratado como objeto de uma construção essencialista animalizadora. Se as anedotas contadas por portugueses eram bem mais pesadas, em contrapartida, eram bem menos frequentes, pois o principal padrão de interação era o de usuários brasileiros se inscreverem no fórum, postarem seguidas mensagens com anedotas sobre os portugueses e, em seguida, cancelarem a subscrição, retirando-se para nunca mais voltar.
Ainda que muitos estereótipos estivessem presentes durante a troca de mensagens, dois elementos predominaram: manifestações atitudinais preconceituosas e condutas discriminatórias, expressas tanto sob a forma de sentenças desqualificadoras quanto de agressões verbais manifestas. Os ânimos, quase sempre acirrados, favoreciam a expressão de estereótipos, preconceitos e discriminações. O conteúdo da maior parte das anedotas étnicas continha alusões depreciativas aos estrangeiros.
Julgamos importante enfatizar as urgentes preocupações dos estudos da época, em particular, os temores suscitados pelo caráter negativo e muitas vezes disruptivo proporcionado pela condição de relativo anonimato imposto pela tecnologia de informação que, na época, se restringia a elementos puramente textuais, embora algumas vezes acrescidos com pitadas de fragmentos pictóricos, como os smiles a indicar o estado de humor do emissor ou a utilização da CAIXA ALTA para assinalar diferenças no tom de voz. Uma outra preocupação se relacionava com a adoção de identidades múltiplas por parte de muitos usuários, vez que já era comum a criação de perfis fictícios e de difícil detecção para a difusão de mensagens cujo conteúdo os usuários não se sentiam à vontade para postar com a identidade oficial.
O desenvolvimento da tecnologia rapidamente tornou obsoleto os BBSs, algo que se acentuou com a introdução, posterior difusão e rápida popularização da internet, então caracterizada como a rede mundial de computadores, numa provável alusão aos recursos introduzidos pela linguagem html. Esta linguagem de programação facilitou a elaboração de conteúdos com uma qualidade estética muito além da possibilitada pelos protocolos mais antigos, como o Gopher. As páginas web, penduradas em sites como o Geocities, se tornaram muito populares, apesar do pouco dinamismo e dos conteúdos relativamente estáticos que conseguiam apresentar, cujo recurso imagético mais dinâmico eram as gifs animadas.
Os anos 1990 testemunharam a rápida adoção de duas modalidades de aplicativos que exerceram um profundo impacto na expressão dos estereótipos e preconceitos: os programas de comunicação instantânea, inicialmente o ICQ e em seguida o MSN Messenger, e a primeira rede social a ganhar popularidade, o Orkut. Os desdobramentos destas duas modalidades ainda não podem ser avaliados com precisão, embora os impactos positivos e negativos venham sendo objeto tanto de valorização quanto de preocupação (Zuboff, 2019).
Um dos aspectos mais marcantes da plataforma Orkut, popularíssima no início do século, foi a criação das comunidades e grupos de interesse, em particular os denominados grupos de desagrado, inicialmente voltados para agregar postagens relativas a temas quase inofensivos, como hábitos de consumo ou repulsa a itens de alimentação ou marcas de produtos comerciais. Esta inocência inicial rapidamente foi substituída pela criação dos famosos grupos de ódio, tendo como objeto categorias sociais específicas, o que passou a despertar um certo interesse entre os psicólogos sociais em estudar estas redes sociais primitivas. Com a criação dos grupos de ódio passaram a ser publicados e começaram a circular livremente manuais rudimentares nos quais eram indicados os passos necessários e requeridos para a criação e difusão deste tipo de associação, acentuando-se as estratégias a serem implementadas para atrair novos membros e manter vivo um estado de ânimo beligerante e combativo.
Se considerarmos as esperanças cultivadas por Schaff, seremos obrigados a admitir que o cenário se tornou bem mais negativo do que imaginara as nossas melhores expectativas, particularmente se compreendermos a condição em que vivemos. Se a preocupação do fim do século passado se consubstanciava em ser capaz ou não de identificar se uma mensagem era escrita ou não pelo usuário que a assinava, hoje temos dificuldades de identificar se uma mensagem postada numa rede social foi escrita por um agente humano ou um robô. Se no passado convivíamos com a insegurança de estar ou não interagindo com uma pessoa que conhecíamos a identidade, hoje convivemos com a certeza de que milhares de perfis são falsos e foram criados com a finalidade de aumentar a popularidade de um usuário ou organização. Se anteriormente a identidade do usuário poderia ser objeto de indagações, nos dias de hoje sabemos que convivemos com postagens elaboradas por empresas constituídas e geridas com a finalidade específica de fazer circular determinadas informações, impor opiniões, modelar tendências de pensamento e defender interesses na maior parte das vezes inconfessáveis e eticamente inadmissíveis.
Este cenário, claro, se reflete no campo de estudos dos estereótipos e preconceitos. Afinal, como discernir a autenticidade de uma mensagem estereotipada se ela pode ter sido elaborada por profissionais contratados por empresas que pouco importam se a informação difundida possui alguma veracidade? Como auscultar a popularidade de uma opinião ou a adesão a um sistema de crenças se as mensagens foram publicadas por uma única fonte e automaticamente replicada por um exército de disparadores automatizados? Como identificar o valor de verdade de uma assertiva expressa em uma mensagem postada em um grupo de usuários de um aplicativo de mensagens se esta pode ter sido o produto do trabalho de uma empresa de reputação duvidosa?
Este conjunto de dúvidas reduziu um pouco o otimismo em torno das novas possibilidades de pesquisa inauguradas pelos modernos meios de ampliação das amostras e pelo acesso a um público mais amplo, particularmente no que concerne às pesquisas de levantamento que utilizam plataformas web. No entanto, essa redução no otimismo não representou um nítido desinteresse por parte dos pesquisadores, sendo mais apropriado festejar o novo horizonte que desponta em meio às latentes possibilidades de estudo e pesquisa ainda que, muitas vezes, pesem as dúvidas sobre a confiabilidade dos resultados. Além da plataforma web para a condução de pesquisas, novas formas de articulação entre a pesquisa dos estereótipos e preconceitos e a tecnologia da informação começam a surgir.
Estes novos desenvolvimentos podem ser exemplificados em uma série de estudos, ora centrados na análise dos conteúdos linguísticos, ora se referindo aos conteúdos imagéticos. Estes novos estudos se apropriam de técnicas da tecnologia da informação como as redes neurais e a aprendizagem de máquina (machine learning) para organizar e analisar informações acumuladas em um corpus de documentos quase impossível de ser manuseado e tratado pelo trabalho manual humano. O tempo e os recursos necessários para análises como as apresentadas nestes estudos impeliram o desenvolvimento de técnicas destinadas a obter, organizar e analisar de forma automática um repertório muito grande de informações e, principalmente, separar os conteúdos espúrios daqueles elaborados e difundidos por humanos.
O estudo de Miltenburg (2016) se volta para a análise dos vieses de julgamento e conteúdos estereotipados impostos às legendas de fotografias postadas na rede Flickr por meio da colaboração coletiva dos usuários (crowdsourcing). A análise de uma fotografia, sem a ajuda de qualquer informação que pudesse contextualizá-la e considerando-se apenas o conteúdo da imagem, seria suficiente para impor um relato neutro e alheio a conteúdos estereotípicos? Segundo relata o autor, muitos profissionais acreditam que sim e admitem que se forem retirados os elementos interpretativos e as informações contextuais, a descrição de uma fotografia centraria o foco apenas nos elementos visuais. Contra esta tese, sugere-se a possibilidade de as descrições das fotografias, por mais cuidadosas que sejam, estarem sujeitas a interpretações estereotipadas.
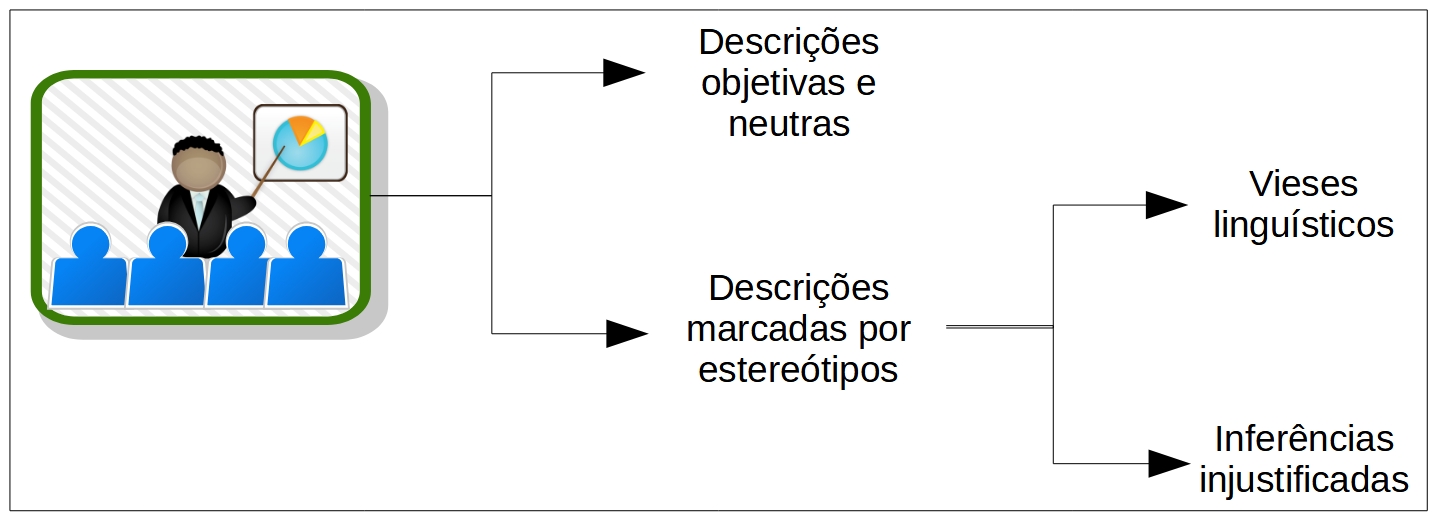
Observemos três possíveis descrições verbais para a imagem reproduzida no canto superior esquerdo da figura 84.
- Uma pessoa aponta para um gráfico projetado na parede, enquanto outras pessoas olham na direção da pessoa que expõe a imagem.
- Um gerente consciencioso, do grupo étnico tal, conduz uma apresentação, enquanto os desatentos subordinados desprezam o relato.
- Um gerente expõe os resultados financeiros da empresa, enquanto os funcionários acompanham atentamente a apresentação.
Os três relatos oferecem possibilidades de descrição das fotografias, embora a primeira possa ser considerada neutra e objetiva e as outras duas marcadas por estereótipos. No primeiro caso, a descrição envolveu, sobretudo, o uso de verbos descritivos (apontar, olhar), o que reduz acentuadamente a possibilidade de intepretações subjetivas do conteúdo textual. Não foram feitas alusões à categoria social dos alvos do julgamento, nem oferecidos indicadores do status, estado psicológico ou possíveis intenções dos atores. Também os elementos contextuais foram reduzidos ao limite, consistindo apenas de informações ostensivas envolvendo elementos proxêmicos e posturais dos atores, inseridos em um ambiente relativamente neutro. Ainda que a descrição não possa ser considerada como inteiramente objetiva e neutra, ela é muito econômica em termos de elementos subjetivos, dificultando sensivelmente a imposição de conteúdos estereotipados.
A segunda sentença introduz vieses linguísticos que a torna muito próxima de uma interpretação marcado por estereótipos. Ela inclui elementos de categorização social, ao aludir à origem étnica do apresentador, e de diferenciação social, ao se referir a gerente e subordinados. A sentença também assegura que o evento é uma apresentação, associando-a a um cargo de mando, ao tempo que considera os subordinados como receptores alheios ao conteúdo exposto. Usualmente os vieses linguísticos resultam do uso profuso de adjetivações ou de marcadores linguísticos como a negação que fornecem indicadores de quanto algumas expectativas a respeito do grupo-alvo dos estereótipos foram violadas.
Uma outra possibilidade de descrição marcada por estereótipos se reflete na terceira sentença; ainda que as referências estereotipadas ao grupo-alvo não estejam presentes, ela introduz inferências que vão além daquilo que pode ser referido estritamente pelo conteúdo da imagem. A utilização de verbos interpretativos como, por exemplo, expor, a alusão a estados metais, ao se acentuar que os funcionários estão atentos a algo, ou mesmo a metas, como é o caso da referência aos resultados financeiros da empresa, assim como a relações posicionais ou ocupacionais expressas na diferenciação entre gerente e subordinados, representam elementos que contribuem para a formulação de inferências que, muitas vezes, não se justificam e podem conduzir a julgamentos marcados pela estereotipização.
O objetivo da diferenciação exposta anteriormente, longe de ser meramente teórica, oferece um método que pode ser incorporado por utilizadores dos sistemas informáticos para a detecção e a redução do uso de estereótipos, vieses e proposições injustificadas. Neste sentido, o autor apresenta algumas sugestões que contribuiriam para este esforço como, por exemplo, produzir as descrições em um ambiente de múltiplos idiomas para expor e consequentemente evitar a expressão de determinados termos e expressões que tenham uma conotação estereotípica em uma língua, evitar o uso de verbos interpretativos para dirimir dubiedades e adotar um modelo de múltiplas camadas de descritores para produzir não apenas uma, mas uma série de referências ao conteúdo das imagens. Adicionalmente, Miltenburg (2016) reconhece que estas estratégias não devem ser tratadas como absolutamente efetivas, pois o uso de conteúdos estereotípicos nas tarefas de colaboração coletiva pode ser considerado inevitável, cabendo aos administradores dos sistemas ajustarem pouco a pouco os algoritmos até que seja alcançado um relativo equilíbrio entre as descrições objetivas e as formulações estereotipadas.
O estudo de Miltenburg (2016) envolveu a aplicação de estereótipos pela comunidade de usuários de um ambiente web, pois os classificadores eram humanos, o que determina uma condição de inevitabilidade de ativação e aplicação de estereótipos. As máquinas, mesmo sendo concebidas, construídas e programadas por seres humanos, fariam um trabalho melhor? Esta é uma questão com que se defrontam muitos pesquisadores na atualidade. O artigo publicado por Bolukbasi, Chang, Zou, Saligrama & Kalai (2016) procura evidenciar que mesmo as inferências geradas por decisões automatizadas e sob a responsabilidade de sistemas inteligentes podem ser comprometidas por inferências indevidas e conteúdos estereotipados. As implicações destas decisões estão relacionadas com as aplicações práticas, vez que aludem a sistemas perfeitamente integrados aos vários domínios da tecnologia da informação, incluindo dispositivos desenhados para a elaboração e descrição de imagens, de sugestões de conteúdos informacionais ou sistemas inteligentes de tomada de decisões. O desafio enfrentado pelos teóricos e programadores está representado na figura 85, na qual podemos identificar uma base de dados, o repertório dos conhecimentos disponíveis, e um motor de inferência responsável pela tomada automática de decisão, o que permite ao sistema fazer uma busca na base de conhecimento e selecionar a resposta apropriada para completar a interrogação apresentada na matriz. A decisão é tomada por um sistema inteligente de aprendizagem de máquina, devidamente treinado por algoritmos especialmente elaborados para vasculhar e encontrar relações entre os elementos incorporados nas matrizes. Por exemplo, conhecendo a relação entre o país França e a capital Paris, e dispondo de um repertório representacional das relações entre os países e as capitais, um sistema inteligente deverá ser capaz, e consegue, depois de algum treinamento, buscar na base de dados a resposta apropriada, selecionando corretamente Londres como a capital da Inglaterra e descartando as opções que não se justam à lógica da inferência. A analogia não é complicada, resumindo-se a concluir que Paris está para a França assim como Londres está para a Inglaterra.
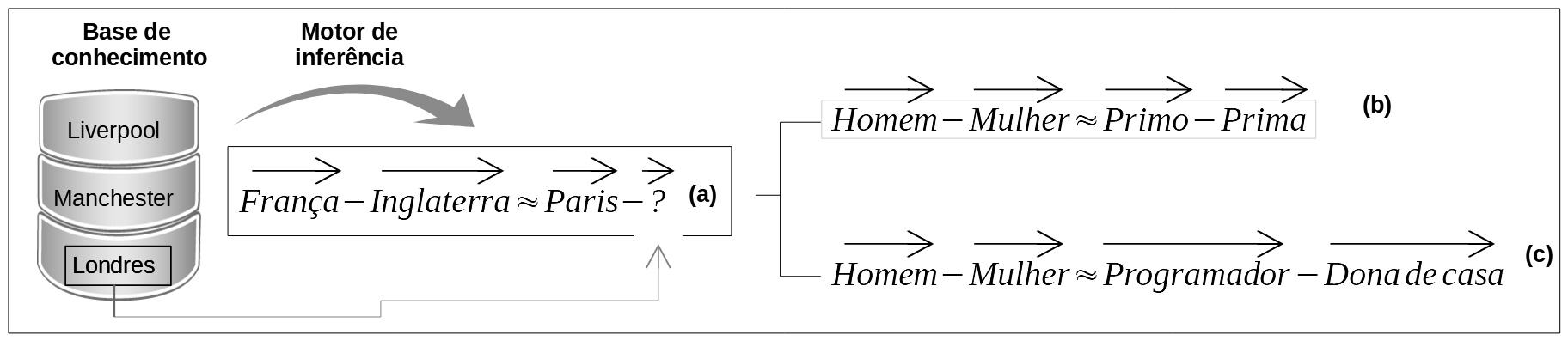
Ser inteligente, entretanto, não é suficiente para evitar erros, a se considerar o resultado do estudo e a dificuldade do sistema de inteligência artificial para evitar respostas que poderiam ser classificadas como estereotipadas ou preconceituosas. Neste particular, agentes com estrutura de hardware de carbono ou de silício não diferem muito. Os pesquisadores passaram a notar que boa parte das decisões tomadas por agentes artificiais inteligentes em consonância com a lógica encontrada na matriz (a) eram legítimas e ofereciam respostas não problemáticas, tal como se observa na matriz (b), na qual se conclui que a palavra primo está para o homem, assim como a palavra prima está para a mulher, uma inferência que dificilmente poderia ser considerada enviesada. Algumas vezes, no entanto, as respostas ferem as suscetibilidades dos usuários mais sensíveis aos problemas relacionados com os estereótipos e preconceitos, tal como se identifica na matriz (c). Um agente informático devidamente treinado por um sistema de aprendizagem de máquina nem sempre oferece respostas idôneas como pode ser vislumbrado no título do artigo ao qual nos referimos, Man is to Computer Programmer as Woman is to Homemaker?, no qual os autores discutem a possibilidade de implementação de algoritmos capazes de evitar a conclusão estereotipada de que uma dona de casa está para as mulheres assim como um programador está para um homem.
Esta situação se mostra particularmente grave se considerarmos que estamos falando de algoritmos de aprendizagem de máquina consagrados pelo uso (Word2Vec e GloVe) e, mais importante, de uma base de informação constituída por um corpus de conhecimento das notícias indexadas pelo Google News, ou seja, constituída fundamentalmente por conteúdos publicados em órgãos de imprensa renomados e redigidos por jornalistas profissionais, o que pretensamente deveria garantir uma linguagem não enviesada e menos sujeita a aproximações preconceituosas. Os autores sinalizaram que os algoritmos estão sendo amiúde embarcados em número cada vez maior de sistemas informáticos, como os mecanismos de busca, de seleção e recrutamento de pessoal e de tradução instantânea, o que amplifica notadamente os vieses presentes na linguagem humana. Para evitar este efeito, eles propuseram alguns algoritmos de eliminação dos vieses, um dos quais parece ter sido capaz de reduzir substancialmente as associações estereotipadas geradas pela técnica de word embebeding, sem comprometer a capacidade de oferecer respostas com associações apropriadas entre as palavras. Este resultado, no entanto, não os eximiu de reconhecer que os vieses estão no mundo e que, por melhor que seja um algoritmo, eles permanece incapaz de conseguir o que não fomos capazes de alcançar.
Um outro artigo que também explora o uso da técnica do word embebbeding para evidenciar como a inteligência artificial se constitui em um recurso de pesquisa importante no estudo dos estereótipos e evidenciou que os algoritmos de word embebbeding mais utilizados na aprendizagem de máquina são capazes de identificar, em um corpo de texto, vieses estereotípicos semelhantes aos cometidos por agentes humanos (Caliskan, Byson, & Narayanan, 2017). No artigo foram estabelecidas analogias entre as evidências apresentadas em pesquisas conduzidas com a aplicação do IAT, um teste de associação implícita muito utilizado para identificar diferenças no tempo de resposta das associações entre vários pares de palavras, e o WEAT, um teste de associações entre as word embebbedings. Segundo as autoras, o sistema artificial foi capaz de aprender as mesmas associações comumente identificadas em agentes humanos, sem que o algoritmo implementado, o GloVe, tivesse qualquer experiência factual com o mundo real e com base apenas na utilização das métricas de co-ocorrência das palavras identificadas no Common Crawl, uma base de dados constituída por cerca de 840 bilhões de unidades de informação, usualmente palavras.
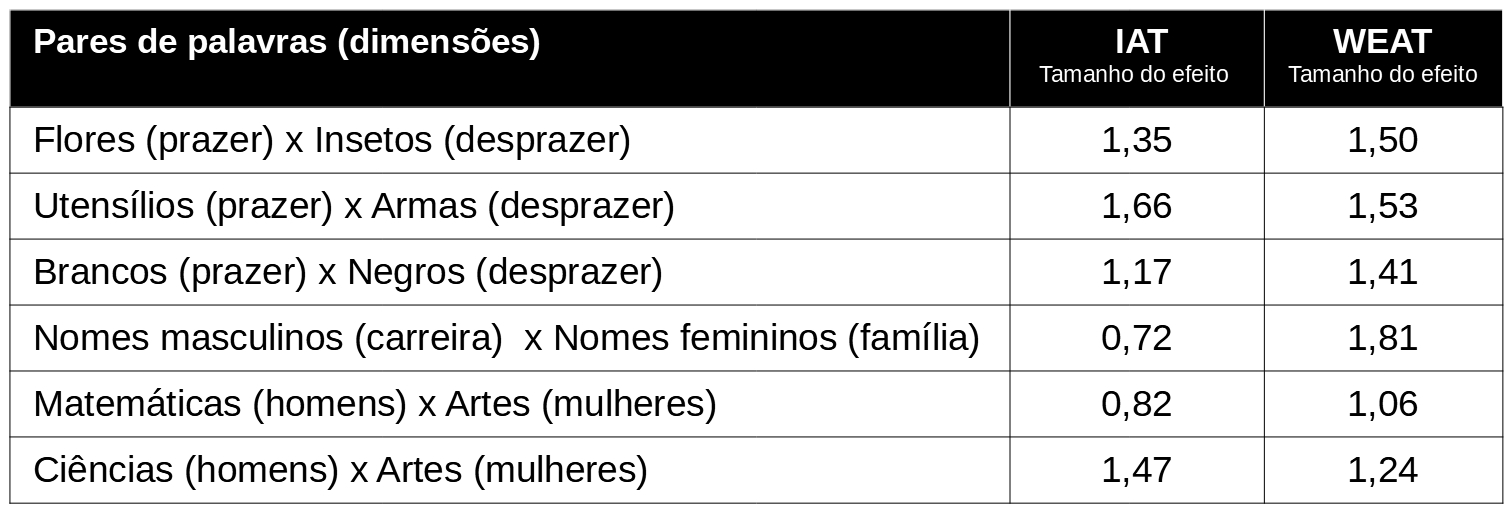
Os resultados apresentados na tabela 9, coluna IAT se referem a estudos conduzidos com agentes humanos e os encontrados na coluna WEAT correspondem ao tamanho do efeito obtido com as associações efetivadas por agentes artificiais. As autoras chamam a atenção que a aprendizagem de máquina não apenas foi capaz de apreender as associações estereotipadas, mas também conseguiu estabelecer associações relativas a outras modalidades de conhecimento, como se observa nos registrados nas duas primeiras linhas da tabela, nos quais podem ser identificadas associações entre os termos flores e utensílios à palavra prazer e entre os termos insetos e armas à palavra desprazer. Ainda que os resultados tenham sido semelhantes, é importante observar que, se as respostas humanas foram obtidas mediante o cálculo pelo pesquisador das diferenças nos tempos de resposta, o algoritmo computacional foi capaz de obter associações semelhantes somente com o uso da inteligência artificial.
As implicações destes resultados representam um importante desafio para o futuro das pesquisas sobre os estereótipos, pois se os vieses dependem substancialmente das regularidades estatísticas associadas com o uso da linguagem, a formulação e hipóteses explicativas sustentadas em mecanismos psicológicos ou sociais podem se tornar prescindíveis. Estas implicações podem levar um pesquisador apressado a defender que a difusão dos estereótipos e preconceitos pode ser explicada simplesmente levando em consideração a maneira particular pela qual fazemos uso da linguagem, uma tese que não nos parece aceitável se considerarmos que o acolhimento, a difusão e a popularização das crenças estereotipadas mantêm uma relação de dependência com processos psicológicos muito diferentes uns dos outros.
O artigo publicado por Garg, Schienbinger, & Jurafsky (2017) explora estas diversas nuances explicativas ao evidenciar como os novos desdobramentos de pesquisa dos estereótipos demandam a utilização conjunta de dados coletados por meios tradicionais, aliados aos obtidos através da tecnologia da informação. Nele, as word embebedings foram utilizadas como insumo para analisar as tendências históricas de expressão dos estereótipos raciais e de gênero na sociedade estadunidense durante um período de quase um século. Para tal, dois algoritmos de inteligência artificial, os referidos Word2Vec e GloVe, foram treinados para apreenderem as relações encontradas em um corpus de texto compreendido pelas notícias publicadas pelo New York Times entre os anos de 1988 e 2005 e, na sequência, comparar os padrões identificados pelo algoritmo de inteligência artificial com os resultados de pesquisas empiricamente conduzidas ao longo deste período.
Os resultados deixaram evidente que as word embebbedings tanto foram capazes de auscultar as mudanças nos estereótipos relacionadas com as transformações históricas da sociedade, como também conseguiram assimilar os estereótipos associados às mudanças demográficas e ocupacionais observadas neste mesmo período, o que sugere que os pesquisadores começam a dispor de recursos analíticos confiáveis para esquadrinhar um conjunto muito grande de dados dispersos por um período de tempo bastante longo.
